by Aswin Vayiravan, Deducely (@Deducely)
Editor: Mei Nagappan (@MeiNagappan), University of Waterloo, Canada
Editor's Note: In a new series of posts (modeled after the Postmortems in Gamasutra.com), we are looking into what worked great and what challenges remain for software developers. We hope to curate many such postmortems in the future! Do email me directly if you have ideas on improving this series of posts. In the first post of this series, I reached out to a small startup company called Deducely in India.
Editor: Mei Nagappan (@MeiNagappan), University of Waterloo, Canada
Editor's Note: In a new series of posts (modeled after the Postmortems in Gamasutra.com), we are looking into what worked great and what challenges remain for software developers. We hope to curate many such postmortems in the future! Do email me directly if you have ideas on improving this series of posts. In the first post of this series, I reached out to a small startup company called Deducely in India.
About Us
Deducely is an AI-powered sales lead generation platform. Usually, software companies have a lead generation team that does a lot of manual work like researching, filtering and qualifying prospects before the sales pitch happens. We have a tool that would remove the burden of repeated manual work in these teams. We use Tensor Flow to learn and track patterns and categorize leads. Also, we use NLTK to learn and extract the required information from unstructured data. We are a small bootstrapped startup headquartered in California but working out of a nondescript village in South India called Thiruparankundram.
What worked great for us?
- The SDLC model: Back in university we had meticulously studied the Pros and Cons of various Software Development Lifecycle models like the Waterfall model, Spiral model, and Agile model. etc. However, when I started my career in Freshdesk (A startup back then), it was surprising to find that I couldn’t fit the software development happening there into any one of these theoretical models! It was a hybrid of everything! Similarly, in our startup Deducely we do not strictly follow any specific model, but the closest model that we could relate to would spiral model. We plan what has to be built, brainstorm the features with our customers and we finally start building one small module at a time, test it, release it and iterate.
- Development Platform: We are Linux lovers and to get Linux into our development devices, we use Vagrant. Although this technology might be a tad bit old, we are huge fans of it! It helps us in isolating various development environments. Even if we ruin the configuration of a particular vagrant environment, we can always spin up a new one from a previous snapshot. This gives us the freedom to go and SUDO without caring much about the consequences! We do not use any IDE. Atom is our text editor of choice.
- Maintaining the code: Git has become the de-facto version control system for code these days. Its decentralized approach takes some time to master but once you start making Git work for you the benefits it offers is unparalleled. Whilst many bigger companies use Github enterprise version or Atlassian Bitbucket, we went ahead with the Gitlab - an open source, self-hosted version control system with a plethora of features like revision control, continuous integration, a container registry, and an issue tracker.
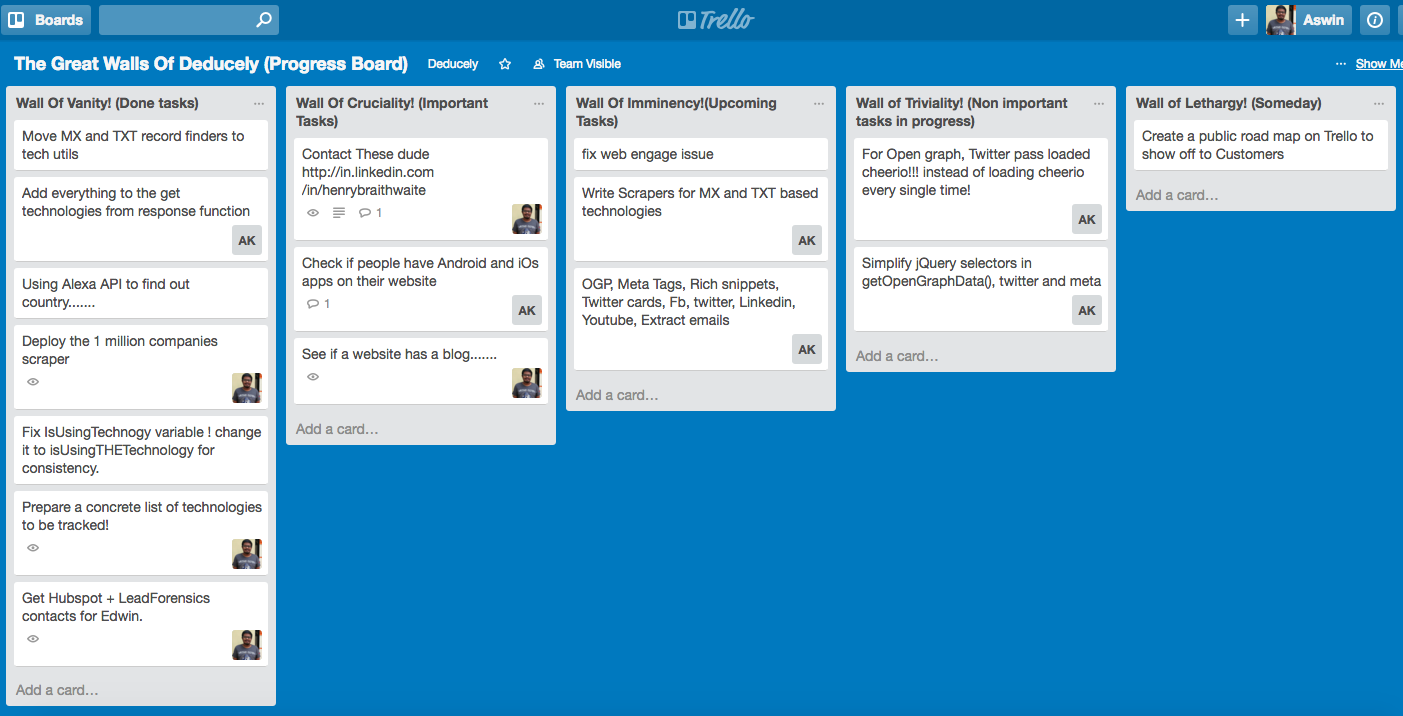
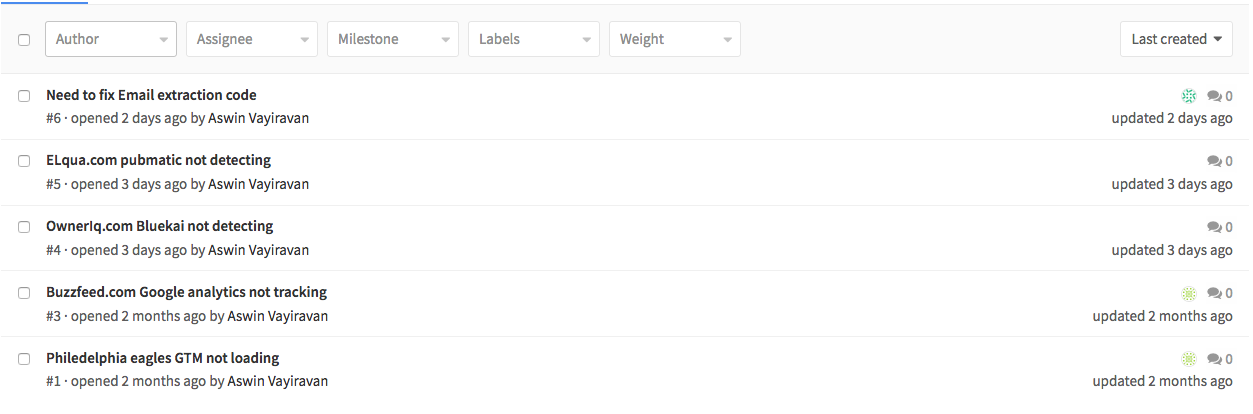
- Tracking the tasks: It all happens with a very simple ToDo board on Trello. We are just two people (Myself and my co-founder Arun Kumar) working full time with a two more remote part-timers. We prioritize tasks and assign it to one person. Before we actually write and integrate different functions, we have a small chat about the function prototype and once the function is coded we run ad-hoc unit tests on the functions. Apart from this, the bugs in our code are tracked using GitLab’s inbuilt bug tracker.
A screenshot of our task board
A screenshot of the issues in one of our repositories
- Storing the data: Initially, there was a lot of arguments for using a conventional database like MySQL or PostgreSQL, but we settled with MongoDB because of its loosely typed Schema. All the queries in MongoDB are simple JS function calls and this is a huge advantage for a full stack JS company like ours. Also, say if we had to edit the schema of a MySQL table containing a billion records it would have been a plain disaster, but with MongoDB, we have better control over the schema and data types. Also backing up, and restoring the DB is fairly painless. Plus replication, fault tolerance and disaster recovery are made simple through MongoDBs replica sets. Though the mongoshell is the best way to connect to MongoDB, we prefer robomongo.
Our biggest challenges
- Callback Hell: We are Javascript aficionados, especially NodeJS. It gives us the ability to do multiple tasks in parallel instead of waiting for IO. We are a two person company and the NPM registry for NodeJS has a lot of trusted open source third party module that we generously incorporate while development. Also, the community support for NodeJS is very mature. If we face a problem, it can be solved in a matter of a few Google searches. However, writing code free of callback hell is a huge challenge not only with node but with any JS flavor. Callbacks, inside callbacks, makes the code unmaintainable and cluttered. We get around callback hell with a library called Bluebird. It makes code, more maintainable and certain code flows that are easily achievable in other languages aren’t easily possible in JS. Such code flows can be achieved with bluebird.
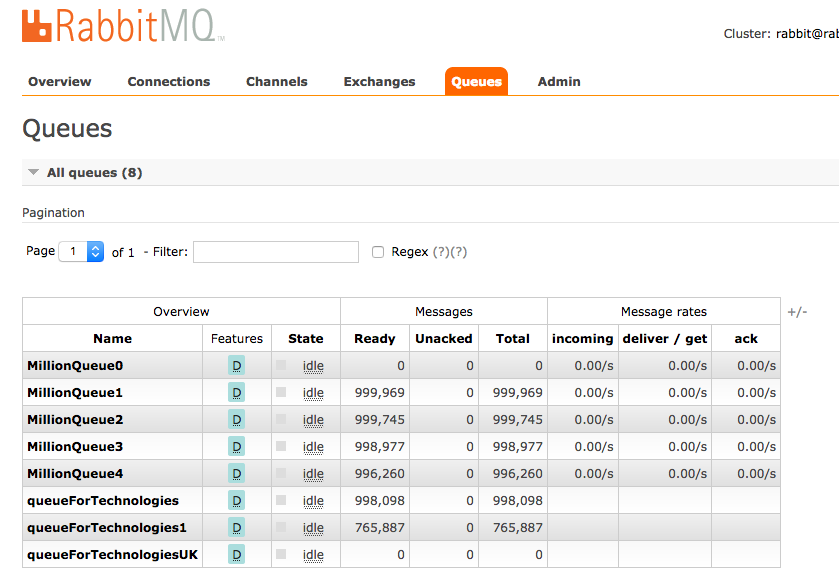
- Sequential execution: We had to scrape data out millions of web pages Javascript gave us a lot of power as it interacted natively with the DOM. However, it had one nasty side effect. In our case, we had to sequentially make millions of HTTP requests. In our initial days, I wrote a snippet to read the list of websites from the database and make those HTTP requests. Since NodeJS is non-blocking controlling the code flow was a huge challenge, and millions of HTTP requests went out but we were never able to get the responses back as these million requests went in one shot! At once! controlling this behaviour of NodeJS was the biggest challenge. JS isn’t very kind to sequential tasks and we work around this restriction via messaging queues - specifically RabbitMQ. It has a powerful API and an easy to use GUI to monitor the status of the queue.
The RabbitMQ dashboard
Data Box
| Developer | Deducely |
| Platform | Linux |
| Number of Developers | 2 Full time and 2 part time |
| Length of development | 1 year |
| Lines of Code | 10K - 100K |







