by Stefan Stanciulescu, IT University of Copenhagen, Denmark (@scas_ITU)
Associate Editor: Sarah Nadi, Technische Universität Darmstadt, Germany (@sarahnadi)
It is often the case that software producers need to create different variants of their system to cater for different customer requirements or hardware specifications.
While there are systematic product line engineering methodologies that support variability (e.g., preprocessor, deltas, aspects, modules), software variants are often developed using clone-and-own (aka copy-paste) since it is a low-cost mechanism without a steep learning curve [1].
Recent collaboration tools such as Github and Bitbucket have made this clone-and-own process more systematic by introducing fork-based development. In this development process, users fork a repository, which creates a traceability link between the two repositories, make changes on their own fork and push changes back to the repository from which they forked (upstream) via pull-requests. 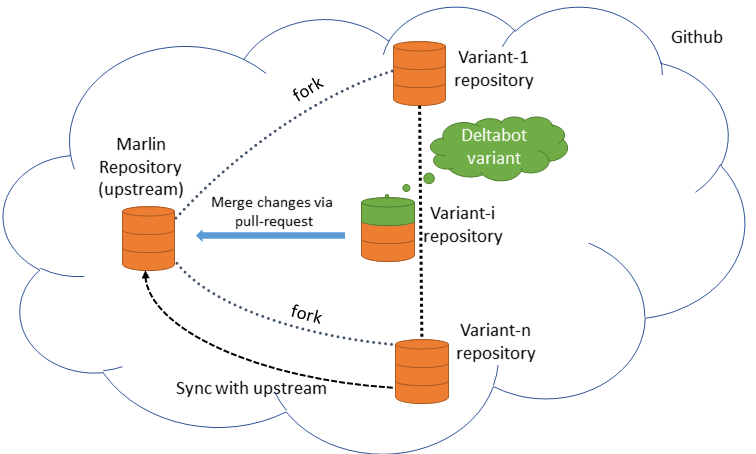
Combining this with a powerful version control system such as Git, better and more efficient variant management can be achieved. The question is how is this done in practice and what difficulties does this process entail? To answer this question, we analyzed Marlin, a 4-year old Github-hosted project that combines clone-and-own with traditional variability mechanisms.
Marlin is a firmware for 3D printers written in C++ that employs variability both through its core code that uses preprocessor annotations, but also through its clones. Started in August 2011, it was forked by more than 2400 people, many of which contribute changes. This is unusual for such a small, recent project in a relatively narrow and new domain.
We looked at Marlin to understand how forking supports the creation of product variants
We sent a survey to 336 fork owners , and got answers from 57 of them. The questions we asked included (1) the criteria they use for integrating changes from the main code base (i.e., upstream) and (2) how they deal with variability. We use these answers to gain a perspective from the user side on the development and maintenance of the forks.
To merge or not to merge?
Fork owners: Most fork owners indicated that it is difficult to merge upstream changes, because their firmware becomes unstable and produces undesired results. In addition, configuring the software is meticulous due to the large number of features and parameters that need to be properly configured. A slight change in these parameters has consequences for the end-user. Therefore, many of the fork owners rarely sync with the main Marlin branch. Another point they made is that only some of the changes are interesting to them, and even though Git allows to selectively apply patches from upstream (cherry-picking), it is still difficult to select what should be merged from upstream and what not.
Marlin Maintainers: If we look from the Marlin maintainers perspective, more than 50% of the main Marlin branch commits came from forks. This suggests that merging changes in the opposite direction is more common. Forks allow users to innovate and bring new ideas to Marlin. However, integrating cloned variants is a difficult task for the maintainers. It is especially problematic when forks introduce new features and want to integrate them into the main codebase, as it may break other people’s variants. To handle this issue, all new feature and variant contributions are not integrated until they are introduced using preprocessor directives. These directives have to be disabled by default in the main configuration of the firmware. This is an attempt to lower the probability of affecting someone else’s variant, with the added side benefit of increasing the stability of the main codebase.
Additionally, maintainers need to ensure that the quality of the clone is within their requirements (implementation, tests, documentation, style adherence), and that they can handle the maintenance and evolution of that variant. In Marlin, this is important as there are many hardware devices that can be used, making it complicated for maintainers to test new variants (which very often means they need to run the printer and print an object). Here is where the community goes the extra mile, with many users using their hardware and printers to test different variants and reporting any issues.
An important aspect is that when changes from a fork get integrated upstream, this fork becomes more popular and visible. For example, in a variant (jcrocholl’s deltabot) there was only one pull-request accepted by the fork owner. When the variant got integrated, there were many more issues and pull-requests that dealt with that variant, and many more changes for that variant got accepted. Finally, jcrocholl’s maintenance efforts were reduced as he did not have to keep in sync with the main Marlin anymore, and push his changes back. Any change related to deltabot was done directly on the main Marlin repository.
Forking vs Preprocessors
In embedded systems, computational resources are limited. Many respondents from our survey explain that memory limitations (Marlin runs on 8-bit Atmega microcontrollers, that have between 4kB and 256kB of flash memory) pushed them to use preprocessor directives to allow excluding code at compilation time, and to experiment with different ideas. On the other hand, we definitely see that forking is the way to go when fast prototyping is needed. It is also useful when changes are not relevant to the other involved people, or just to store configurations of a variant. The latter is heavily used in Marlin (around 200 forks only store configurations of the firmware), and it is a very light and efficient mechanism.
Lessons learnt
Based on the above survey results as well as more detailed analysis of the Marlin project structure and development history, we derive the following guidelines for fork-based development.
- Fork to create variants and to support new configurations. It is easy, efficient and lightweight, and using Github’s forking, we get traceability for free.
- Use preprocessor annotations for flexibility and to tackle memory constraints when needed, both in a fork and in the main branch.
- Keep track of variants by adding a description for each fork created and maintain that description.
- Merge upstream often to reduce maintenance and evolution efforts of cloned variants.
Recent tools and techniques (Git, Github, forking) can deal to some degree with the complex task of variant development. With the large adoption of Github, it seems that we are already heading towards that direction. Adopting new tools and techniques is a long process, and there are still many challenges that lie ahead, but we are one step closer in understanding how to offer better tool support for variant management.
References
[1] Yael Dubinsky, Julia Rubin, Thorsten Berger, Slawomir Duszynski, Martin Becker, Krzysztof Czarnecki. An Exploratory Study of Cloning in Industrial Software Product Lines. CSMR 2013: 25-34
More detailed information about Marlin, variants and its evolution can be found online. http://itu.dk/people/scas/papers/ICSME2015-Marlin-preprint.pdf
If you liked this article, you might also enjoy reading:
- K. Schmid, E.S. de Almeida, "Product Line Engineering," in IEEE Software 30, 4, , 2013, pp. 24-30.
- D. Spinellis, "Git", IEEE Software, 29, 3, 2012. pp. 100-101.
- J. Bosch, R. Capilla, R. Hilliard, "Trends in Systems and Software Variability [Guest editors' introduction]", IEEE Software, 32, 3, 2015, pp. 44-51.

